以数据点灯:解码 Ai 与 Crypto 的再编辑
原文标题:The Data Must Flow
原文作者:SHLOK KHEMANI
原文来源:Decentralised.co
编译:DefiLlama 24
1,500 万张图像 22,000 个类别
这是 ImageNet 的数据集大小,当时普林斯顿大学的助理教授李飞飞想要创建它。她希望这样做能够帮助推动计算机视觉这一停滞不前的领域的发展。这是一个大胆的尝试。22,000 个类别至少比以前创建的任何图像数据集都多两个数量级。
她的同行们认为,构建更好的人工智能系统的答案在于算法创新,他们质疑她的智慧。“我越和同事们讨论 ImageNet 的想法,我感到越孤独。”
尽管遭到怀疑,飞飞和她的小团队——包括博士候选人 Jia Deng 和几名时薪 10 美元的本科生——开始标记来自搜索引擎的图像。进展缓慢而痛苦。Jia Deng 估计,按照他们的速度,完成 ImageNet 将需要 18 年——没有人有这个时间。就在这时,一位硕士生向飞飞介绍了亚马逊的 Mechanical Turk,这是一个通过众包来自世界各地的贡献者完成“人类智能任务”的市场。飞飞立刻意识到这正是他们所需要的。
在 2009 年,也就是飞飞开始她生命中最重要的项目三年后,在一支分散的全球劳动力的帮助下,ImageNet 终于准备好了。在推进计算机视觉的共同使命中,她已经尽了自己的一份力。
现在,轮到研究人员开发算法,利用这个庞大的数据集帮助计算机像人类一样观察世界。然而,在最初的两年里,并没有发生这种情况。这些算法几乎没有比 ImageNet 之前的状态表现得更好。
飞飞开始怀疑她的同事们是否一直对 ImageNet 是徒劳的努力的看法是正确的。
然后,在 2012 年 8 月,就在飞飞放弃希望她的项目能激发她设想的变化时, Jia Deng 急切地打电话告诉她关于 AlexNet 的消息。这个新算法在 ImageNet 上训练,超过了历史上所有的计算机视觉算法。由多伦多大学的三位研究人员创建,AlexNet 使用了一种几乎被抛弃的 AI 架构,称为“神经网络”,并且超出了飞飞最狂野的预期。
展开全文
在那一刻,她知道自己的努力已经结出果实。“历史刚刚被创造,世界上只有少数人知道。” 李飞飞在她的回忆录《我看到的世界》中分享了 ImageNet 背后的故事。
ImageNet 结合 AlexNet 之所以具有历史意义,有几个原因。
我们都读过也听过诸如“数据是新石油”和“垃圾进,垃圾出”这样的谚语无数次。如果这些话不是关于我们世界的基本真理,我们可能会对它们感到厌烦。多年来,人工智能在幕后逐渐成为我们生活中越来越重要的一部分——影响着我们阅读的推文、观看的电影、我们支付的价格以及我们被认为值得的信用。所有这些都是通过精心追踪我们在数字世界中的每一个举动来收集数据所驱动的。
但是在过去两年里,自从一个相对不知名的初创公司 OpenAI 发布了一个名为 ChatGPT 的聊天机器人应用以来,人工智能的重要性已经从幕后走到了台前。我们正处于机器智能渗透到我们生活每一个方面的风口浪尖。随着关于谁将控制这种智能的竞争升温,对驱动它的数据的需求也在不断升温。
这就是这篇文章的主题。我们讨论了人工智能公司所需的数据规模和紧迫性,以及它们在获取数据时所面临的问题。我们探讨了这种永不满足的需求如何威胁到我们对互联网和数十亿贡献者的热爱。最后,我们介绍了一些新兴的初创公司,它们正在使用加密货币来解决这些问题和担忧。
在我们深入讨论之前,快速说明一下:这篇文章是从训练大型语言模型(LLMs)的角度撰写的,而不是所有 AI 系统。因此,我经常交替使用“AI”和“LLMs”。虽然这种用法在技术上不准确,但适用于 LLMs 的概念和问题,特别是关于数据的问题,也适用于其他形式的 AI 模型。
数据
大型语言模型的训练受三个主要资源的限制:计算、能源和数据。公司、政府和初创公司同时在争夺这些资源,背后有大量资本支持。在这三者中,对计算的竞争是最激烈的,部分归功于 NVIDIA 股价的急速上涨。
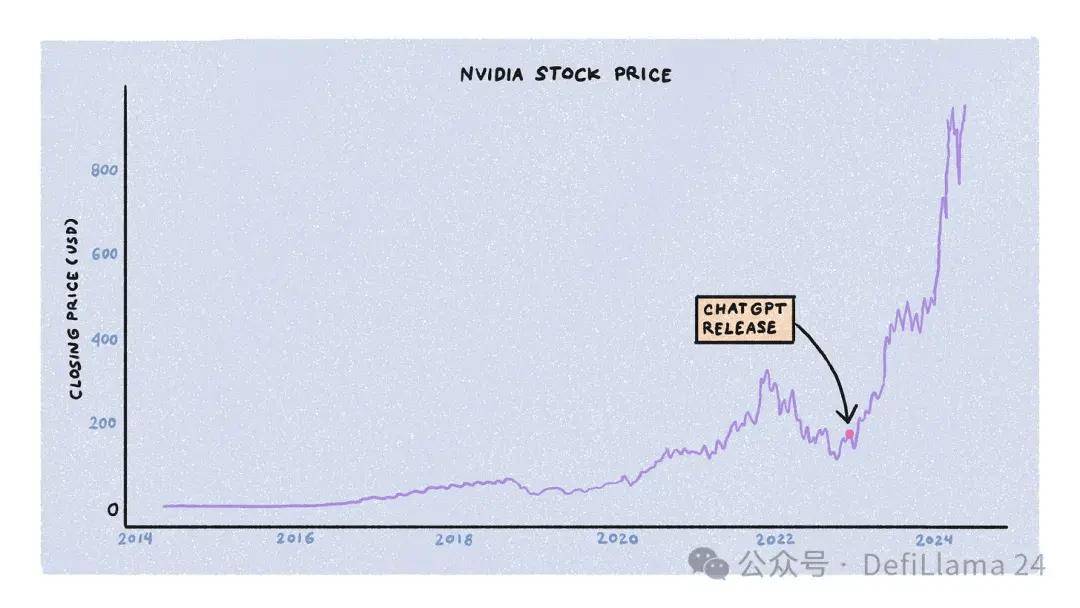
训练 LLMs 需要大量的专业图形处理单元 (GPU) 集群,特别是 NVIDIA 的 A100、H100 和即将推出的 B100 型号。这些不是你可以从亚马逊或当地电脑商店现成购买的计算机。相反,它们成本高达数万美元。NVIDIA 决定如何将其供应分配给 AI 实验室、初创公司、数据中心和超大规模的客户。
在 ChatGPT 发布后的 18 个月里,GPU 需求远远超过了供应,等待时间高达 11 个月。然而,随着最初的狂热尘埃落定,供需动态正在正常化。初创公司倒闭、训练算法和模型架构的改进、其他公司的专用芯片的出现,以及 NVIDIA 增加生产,所有这些都有助于增加 GPU 的可用性和价格的递减。
第二,能源。在数据中心运行 GPU 需要大量的能源。据某些估计,到 2030 年,数据中心将消耗全球能源的 4.5%。由于这种激增的需求给现有的电网带来压力,科技公司正在探索替代能源解决方案。亚马逊最近以 6.5 亿美元购买了一座由核电站供电的数据中心。微软已经聘请了一个核技术负责人。OpenAI 的Sam Altman 支持了像 Helion、Exowatt 和 Oklo 这样的能源初创公司。
从训练 AI 模型的角度来看——能源和计算只是商品。使用 B100 而不是 H100,或使用核能而不是传统能源可能会使训练过程更便宜、更快、更高效——但这不会影响模型的质量。换句话说,在创建最智能和最像人类的 AI 模型的竞赛中,能源和计算是基本要素,而不是区分因素。
关键资源是数据。
James Betke r是 OpenAI 的研究工程师。用他自己的话说,他已经训练了“比任何人都有权训练的更多生成模型”。在一篇博客文章中,他指出,“在相同的数据集上训练足够长的时间,几乎所有具有足够权重和训练时间的模型都会收敛在同一点上。”这意味着区分一个 AI 模型与另一个 AI 模型的是数据集。没有别的。
当我们提到一个模型为“ChatGPT”、“Claude”、“Mistral” 或 “Lambda” 时,我们谈论的不是架构、使用的 GPU 或消耗的能源,而是它所训练的数据集。
如果数据是 AI 训练的食物,那么模型就是吃他们的东西。
训练一个最先进的生成模型需要多少数据?
答案:很多。
GPT-4,在其发布一年多后仍被认为是最好的大型语言模型,它在估计 1.2 万亿个 token(或约 9000 亿个单词)上进行了训练。这些数据来自公开可用的互联网,包括维基百科、Reddit、Common Crawl(一个免费开放的网络爬取数据存储库)、超过一百万个转录 YouTube 数据小时,以及像 GitHub 和 Stack Overflow 这样的代码平台。
如果你认为那是很多数据,请稍等。在生成 AI 中有一个概念叫做“Chinchilla Scaling Laws”,它指出,对于给定的计算预算,在较大数据集上训练较小模型比在较小数据集上训练较大模型更有效。如果我们推断 AI 公司为训练下一代 AI 模型(如 GPT-5 和 Llama-4 )所分配的计算资源——我们发现这些模型预计需要五到六倍的计算能力,使用高达 100 万亿个 token 进行训练。
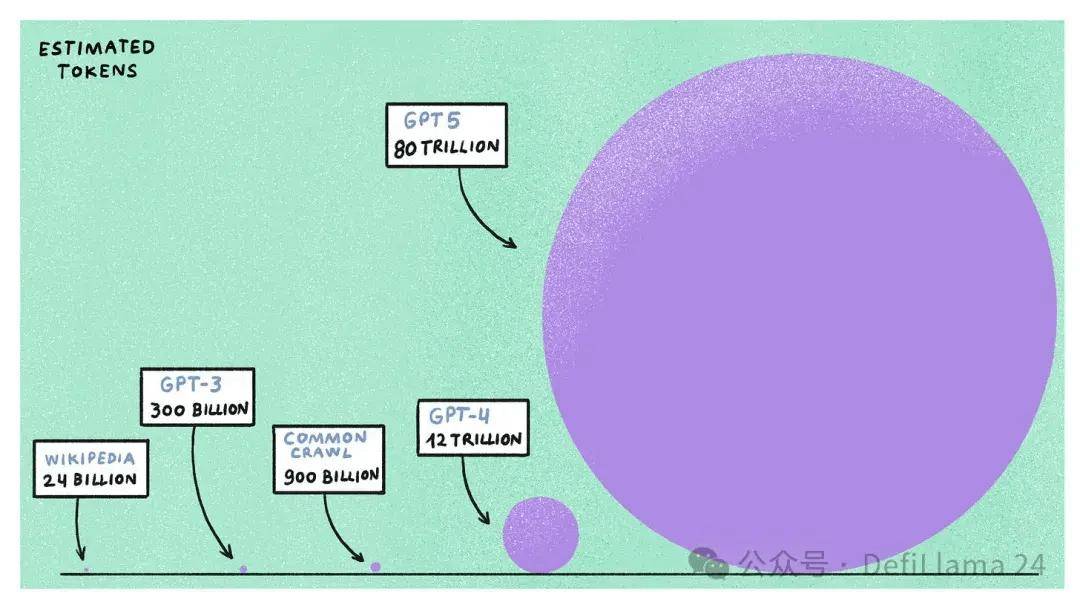
由于大多数公共互联网数据已经被爬取、索引并用于训练现有模型,那么额外的数据从哪里来?这已经成为 AI 公司的前沿研究问题。有两种方法可以解决这个问题。一种是你决定使用由 LLMs 直接生成的合成数据,而不是由人类生成。然而,这种数据在使模型变得更智能方面的有效性尚未经过测试。
另一种选择是简单地寻找高质量数据而不是合成创建。然而,获取额外数据具有挑战性,特别是当 AI 公司面临的问题不仅威胁到未来模型的训练,还威胁到现有模型的有效性时。
第一个数据问题涉及法律问题。尽管 AI 公司声称他们在“公开可用数据”上训练模型,但其中很多是受版权保护的。例如,Common Crawl 数据集包含了来自《纽约时报》和美联社等出版物的数百万篇文章,以及其他受版权保护的资料,如出版的书籍和歌词。
一些出版物和创作者正在对 AI 公司采取法律行动,声称其侵犯了他们的版权和知识产权。《泰晤士报》起诉 OpenAI 和微软“非法复制和使用《泰晤士报》独特且有价值的作品”。一群程序员提起集体诉讼,质疑使用开源代码训练 GitHub Copilot(一种流行的 AI 编程助手)的合法性。
喜剧演员萨拉·西尔弗曼和作家保罗·特雷姆布莱也因未经许可使用他们的作品而起诉 AI 公司。
其他人则通过与 AI 公司合作来拥抱变革的时代。《美联社》、《金融时报》和 Axel Springer 都与 OpenAI 签署了内容许可协议。苹果正在与 Condé Nast 和 NBC 等新闻机构探索类似的合作。谷歌同意每年支付 6000 万美元以获取 Reddit API 的使用权来训练模型,Stack Overflow 也与 OpenAI 达成了类似的协议。Meta 据考虑直接购买出版商西蒙与舒斯特。
这些合作与 AI 公司面临的第二个问题相一致:开放网络的关闭。
互联网论坛和社交媒体网站已经意识到 AI 公司通过利用他们平台上的数据训练模型所创造的价值。在与谷歌(以及未来可能的其他 AI 公司)达成交易之前, Reddit 开始对其之前免费的 API 收费,关闭了其流行的第三方客户端。类似地,Twitter 限制了对其 API 的访问并提高了价格,埃隆·马斯克使用 Twitter 数据为他自己的 AI 公司 xAI 训练模型。
即使是较小的出版物、同人小说论坛和互联网的其他小众角落,它们生产了供大家自由消费的内容,并通过广告(如果有的话)获利,现在也开始关闭。互联网原本被设想为一个神奇的网络空间,每个人都可以在这里找到一个分享他们独特兴趣和怪癖的部落。这种魔力似乎正在慢慢消散。
诉讼威胁、数百万内容交易的日益增长趋势,以及开放网络的关闭,这三个因素的结合产生了二个影响: